








DAY 1
The Micropole team is hit by the crowd, covid seems far away... The AWS re:Invent, which traditionally takes place every year in Las Vegas, is an event not to be missed, as it provides a synoptic view of the major directions of the Cloud and Data market, and the new technologies that AWS is continually adding to its already extensive catalog of services, as well as instructive customer feedback on best practices for implementing these technologies and the gains obtained. The 2023 edition, which welcomes more than 60,000 people this year, is no exception to the rule... And cEvery session, whether it's about innovation, technology, case studies, or learning labs, offers something for everyone.
Generative AI Dominates Discussions
Integrating with various AWS services or tools such as Tableau or Salesforce, generative AI promises productivity gains across all industries. But these technologies also bring their share of questions: beyond the buzz, what value can really be extracted from it and what risks must be taken into account?
One session in particular, entitled "A leader's guide to generative AI", offered some interesting avenues:
- Success depends on the right choice of tools; It is essential to select the right model carefully.
- A solid foundation is a must; It is crucial to establish a reliable data foundation.
- Enthusiasm and skepticism will be present; We need to focus on the problem rather than the solution.
- Learning new skills is key to rethinking work; It's time to train your teams and reimagine work processes.
- The changes brought about by the IA create new risks and liabilities; These new challenges must be recognized and accepted.
- Value and new ideas are growing explosively; it's time to start working with generative AI.
These precepts remind us that integratinggenerative AI is a process that requires discernment, preparation and a willingness to embrace change.
The Evolution of Fundamental AWS Services
Beyond the subject of generative AI, it is interesting to look at the evolution of fundamental AWS services to set up a modern and scalable data base with reliable, usable and documented data, a prerequisite for any desire to develop a reliable and efficient AI or GenAI model.
Whether or not you're new to migrating your data platforms to the cloud, it's worth noting that AWS offers a number of very useful services that make it much easier to do so, from automatically discovering and evaluating your data sources (AWS DMS Fleet Advisor) to migrating your data (AWS DMS) to converting your database schemas (AWS Schema Conversion). The newly released AWS Serverless DMS even supports the automatic allocation of network infrastructure and resources needed to migrate your data sources (whether on-premises or in the cloud) in a secure manner.
AWS DMS (Data Migration Service) has been used by more than a million users since its launch, and AWS itself has used this service to migrate its on-premises data sources (500K databases, 500PB of data) to its own cloud in recent years, proof that this service is scalable.
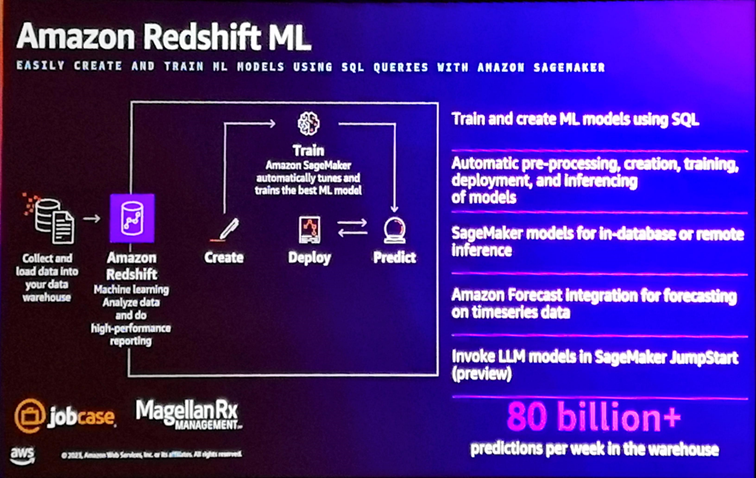
Amazon Redshift benefits from a number of evolutions, including the integration of Amazon Forecast to make predictions on temporal data from Redshift, the invocation of LLM models developed with SageMaker Jumpstart, and the ability to create and train machine learning models (based on SageMaker)) using SQL directly from the Redshift Query Editor. It also provides a notebook-like experience for managing and executing SQL queries and performing data exploration and analysis.
Also of note is the native integration between Amazon Kinesis and Redshift, which allows data from a data stream to be ingested into Redshift in near real-time, and the ability to invoke a prediction function on this data via Redshift ML (the example was the detection of fraudulent bank transactions in real time).
Also announced last night during the Keynote by Peter DeSantis was the introduction in Redshift Serverless of a query optimizer based on a machine learning model designed to predict the complexity and costs of query execution and to automatically trigger the autoscaling of the Redshift infrastructure (within the limits of the maximums indicated by the customer) when a complex query is likely to block or delay the execution of classic queries (in the old version, auto-scaling was triggered based on the number of concurrent queries, regardless of their complexity).
Last but not least, AWS is focusing this year on Data Governancewith the introduction in May ofAmazon DataZone, a data management service for discovering, inventorying, analyzing, documenting, sharing and securing access to your data. This service, which interfaces natively with Glue Catalog to collect metadata from your sources, offers a data portal called Amazon DataZone portal, enabling you to create an ontological dictionary made up of Business terms,
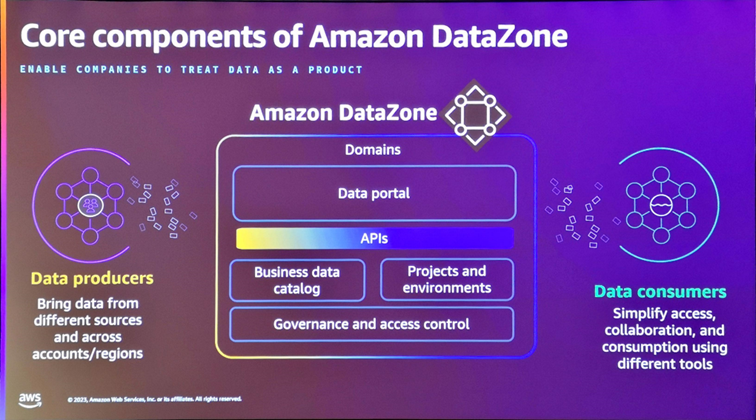
and associate them with data objects (Assets) and/or their attributes. This is a welcome initiative because it interfaces natively with the main AWS data services (S3, Redshift, Aurora, etc.) and thus greatly simplifies the creation and maintenance of a data portal. It would be interesting to see the upcoming integration with AWS Macie, a service that can automatically detect the sensitivity of analyzed data stored on S3. To be continued...

Charles Moureau
Director Cloud4Data

Thomas Dallemagne
Partner Advisory


