








JOUR 1
L’équipe Micropole est frappée par la foule, le covid semble bien loin… L’AWS re:Invent qui a traditionnellement lieu tous les ans à Las Vegas est un événement à ne pas rater, car il permet d’obtenir une vision synoptique des grandes orientations du marché du Cloud et de la Data, et des nouveautés technologiques qu’AWS ajoute continuellement à son catalogue de services déjà bien fourni, mais également des retours d’expérience clients riches d’enseignement concernant les bonnes pratiques de mise en œuvre de ces technologies et les gains obtenus. L’édition 2023 qui accueille plus de 60 000 personnes cette année ne déroge pas à la règle… Et chaque session, qu’elle aborde l’innovation, la technologie, des études de cas ou les labos d’apprentissage, offre quelque chose pour tous.
L’IA générative domine les discussions
S’intégrant dans différents services AWS ou dans des outils tels que Tableau ou Salesforce, l’IA générative promet des gains de productivité à travers tous les secteurs d’activité. Mais ces technologies amènent également leur lot de questions : au-delà du buzz, quelle valeur peut-on réellement en extraire et quels risques doivent être pris en compte ?
Une session en particulier, intitulée “A leader’s guide to generative AI”, a proposé quelques pistes intéressantes :
- La réussite passe par le choix judicieux des outils ; il est essentiel de sélectionner le bon modèle avec soin.
- Une base solide est indispensable ; il est crucial d’établir une fondation de données fiable.
- L’enthousiasme et le scepticisme seront présents ; il faut se concentrer sur le problème plutôt que sur la solution.
- L’acquisition de nouvelles compétences est essentielle pour repenser le travail ; il est temps de former vos équipes et de réimaginer les processus de travail.
- Les changements apportés par l’AI engendrent de nouveaux risques et responsabilités ; il faut reconnaître et accepter ces nouveaux défis.
- La valeur et les nouvelles idées connaissent une croissance explosive ; il est temps de commencer à travailler avec l’AI générative.
Ces préceptes nous rappellent que l’intégration de l’AI générative est une démarche qui exige discernement, préparation et une volonté d’embrasser le changement.
L’évolution des services AWS fondamentaux
Au-delà du sujet de l’IA générative, il est intéressant de se pencher sur l’évolution des services AWS fondamentaux permettant de mettre en place un socle de données moderne et scalable avec des données fiables, exploitables et documentées, condition préalable à toute velléité de développement d’un modèle d’IA ou GenAI fiable et performant.
Que vous ayez ou non débuté la migration de vos plates-formes de données vers le Cloud, il est intéressant de noter qu’AWS propose un certain nombre de services très utiles facilitant grandement cette opération, depuis la découverte et l’évaluation automatique de vos sources de données (AWS DMS Fleet Advisor) jusqu’à la migration de vos données (AWS DMS) en passant par la conversion de vos schémas de base de données (AWS Schema Conversion). AWS DMS Serverless disponible depuis peu, prend même en charge l’allocation automatique de l’infrastructure réseau et des ressources nécessaires pour opérer la migration de vos sources de données (qu’elles soient on premises ou en Cloud) de manière sécurisée.
AWS DMS (Data Migration Service) a été utilisé par plus d’un million d’utilisateur depuis son lancement, et AWS a lui-même utilisé ce service pour opérer la migration de ses sources de données on premises (500K bases de données, 500PB de données) vers son propre Cloud ces dernières années, preuve que ce service est scalable.
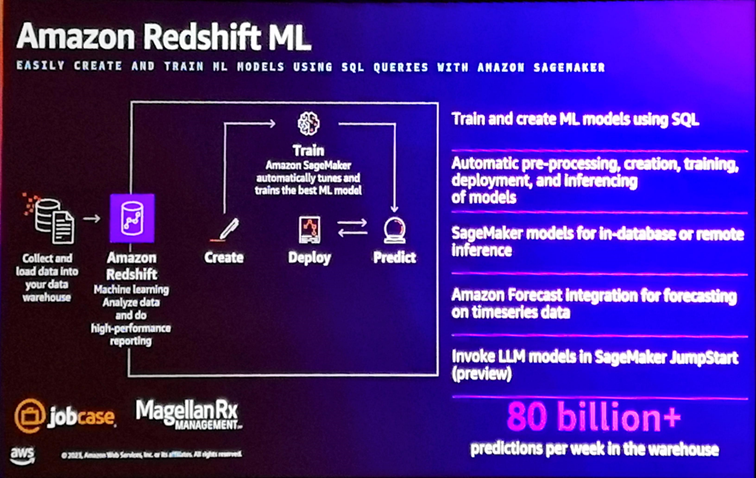
Amazon Redshift bénéficie de nombreuses évolutions, dont l’intégration d’Amazon Forecast permettant d’effectuer des prévisions sur des données temporelles depuis Redshift, l’invocation de modèle LLM développés avec SageMaker Jumpstart, ou encore la possibilité de créer et d’entraîner des modèles de Machine Learning (basés sur SageMaker) à l’aide du langage SQL directement depuis l’éditeur de requêtes Redshift. Il propose également une expérience de type Notebook pour gérer et exécuter ses requêtes SQL et effectuer de l’exploration et de l’analyse de données.
À noter également l’intégration native entre Amazon Kinesis et Redshift qui permet d’ingérer en quasi-temps réel dans ce dernier des données issues d’un flux de données, ou encore la possibilité d’invoquer une fonction de prédiction sur ces données via Redshift ML (l’exemple correspondait à la détection de transactions bancaires frauduleuse en temps réel).
Également annoncé hier soir lors de la Keynote par Peter DeSantis l’introduction dans Redshift Serverless d’un optimiseur de requêtes basé sur un modèle de Machine Learning destiné à prédire la complexité et les coûts d’exécution des requêtes et de déclencher automatiquement l’auto scaling de l’infrastructure Redshift (dans la limite des maxima indiqués par le client) lorsqu’une requête complexe est susceptible de bloquer ou retarder l’exécution de requêtes classiques (dans l’ancienne version, l’auto-scaling était déclenché en fonction du nombre de requêtes concurrentes, indépendamment de leur complexité).
Enfin, AWS fait la part belle cette année à la Data Governance, avec l’introduction en mai dernier d’Amazon DataZone, un service de gestion des données permettant de découvrir, inventorier, analyser, documenter, partager et sécuriser l’accès à vos données. Ce service, qui s’interface nativement avec Glue Catalog pour collecter les métadonnées de vos sources, offre notamment un portail de données baptisé Amazon DataZone portal permettant de créer un dictionnaire ontologique fait de Business terms,
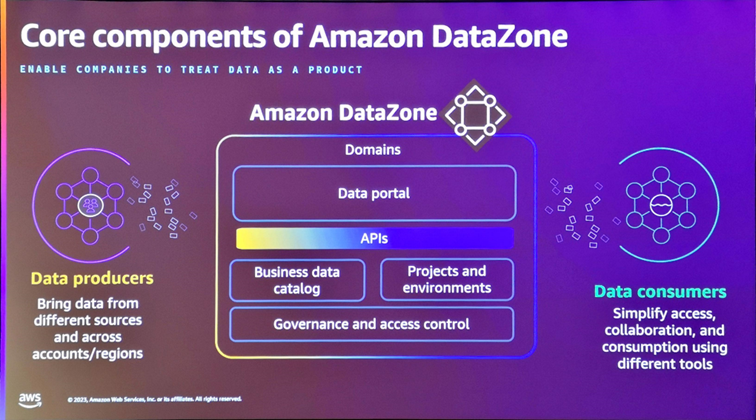
et d’associer ces derniers aux objets de données (Assets) et/ou à leurs attributs. Une initiative bienvenue car elle s’interface nativement avec les principaux services de données AWS (S3, Redshift, Aurora…) et simplifie ainsi grandement la création et l’alimentation d’un portail de données. Il serait intéressant de voir l’intégration prochaine avec AWS Macie, un service qui sait automatiquement détecter la sensibilité des données analysées stockées sur S3. Affaire à suivre…

Charles Moureau
Directeur Cloud4Data

Thomas Dallemagne
Partner Advisory


